The Challenge
Biodiversity literature is dedicated to the identification, documentation, and categorization of plants, fungi, animals, and other living organisms. Correctly extracting the name of an organism within these documents involves finding the entire scientific name–including the genus, specific epithet, and author name (a plant name shown below). Extracting these names allows biologists to access documents about a species more comprehensively, and to track an organism’s history of documentation by botanists, which includes biological changes and changes in how scientists describe them. However, correctly finding organisms by their scientific names is made difficult by ambiguous abbreviations, changing botanical and zoological codes and conventions, and poor data quality.
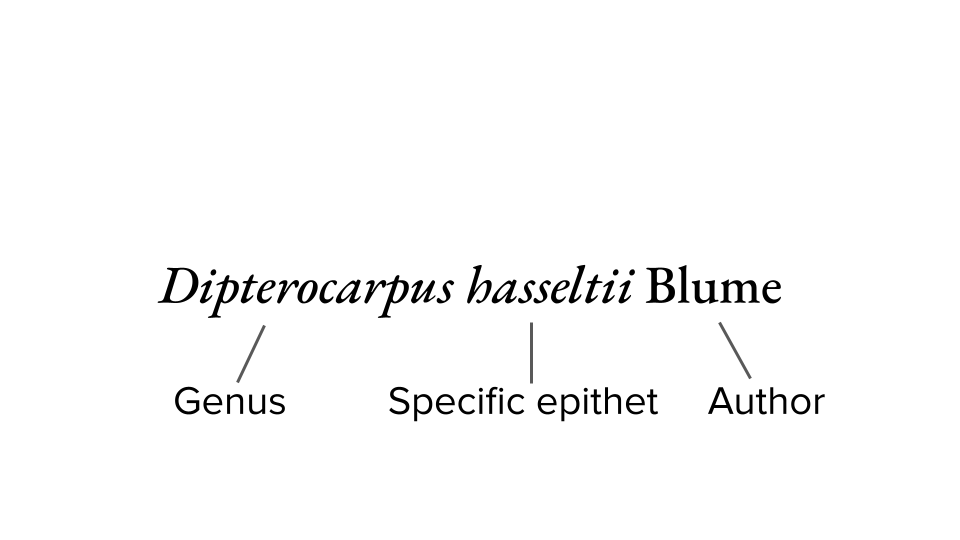
The Discovery and Exploration Process
During my time as a Siegel Family Endowment PiTech PhD Impact Fellow, I partnered with the New York Botanical Gardens, and specifically Damon Little and Nelson Salinas, to employ deep learning and context-based language modeling to create a system that can extract scientific plants in biodiversity literature. This is the second version of an existing project, created by Little, that can be accessed through a web interface: Quaesitor. In this new stage of the project, using a large language model allows for the language around a scientific name, such as location or descriptor, to be used as an informative clue as to what the name might be. This project culminated in a text-generative language model. This model takes a selection of text from biodiversity literature as input, and outputs a sequence of text in the form of a scientific name. Ideally, this model returns three pieces of information: 1) the genus, 2) the specific epithet, and 3) the author (the person who first described the plant in the scientific literature).
You can access the model, t5-base-sci-names, at its HuggingFace repository. You can also play with the fine-tuned model or review the fine-tuning code with Google Colab.
Multilingual botanical language model
The botanical and zoological communities have their own changing norms, codes, and goals. Moreover, even though they are specialized research communities, their literature exists across centuries and in many languages, requiring the model to be multilingual. In biodiversity literature, even a single document often shifts between languages. For example, until 2012, it was a standardized convention that every newly discovered plant would be—at least in part—described in Botanical Latin (a language designed for describing plants, with only relative similarity to Classical Latin). There are also a range of types of documents, from checklists to revisions, introductions, etc., all of which have text structured in unique ways. For these reasons, a domain-agnostic and generalizable language model, which is often trained on Wikipedia entries or books, is a poor fit for the type of documents it will analyze in practice. Therefore, this project requires domain adaptation, a process of training an existing language model to better fit the specific domain.
As a first step, I fine-tuned a T5-Base text-generative model to the task at hand: predicting scientific names. During fine-tuning, the model was given hand-annotated examples of input and output texts, to teach it to learn to output an expanded scientific name, when possible. Text generation models can be improved through simple changes to the structure of output prompts and formatting, so I compared the accuracy of the generated text when given a clearer structure, like “genus = [genus_name]” and “author = [author_name]”.
An example of the T5 model’s text generation is as follows:
| Original Name | Text Input | Formatted Output |
| Dipterocarpus hasseltii Blume, D. trinervis | MINDORO, For. Bur, 4101, 4106 Merritt, May 1906, in flower and fruit. Common names : anahaun (Tag.) , apitong (Tag.). Distribution: forests of West Java; the Philippines. 6. Dipterocarpus hasseltii Blume Fl. Javae (1828-29) 22, t… Buds and young branchlets glabrous. Terminal buds elongate, at-tenuate, curved. Leaves much smaller than those of D. trinervis, oval, acute, base subcuneate, | genus = Dipterocarpus, epithet = hasseltii, author = Blume, genus = Dipterocarpus, epithet = trinervis, author = |
| S. batttafnensis | It is called ‘ Mendora ‘ where it grows. Wood heavy, hard, yellow, smooth, and shining. 5. SUNAPTEA, Griff. Trees ; fl. in short axillary panicles, with large deciduous bracts; sep. and pet. 5; stam. 15, apiculate ; fruit-sep. all enlarged, 2 much more so than the others, wing-like, erect, loosely surrounding the nut, the bases not thickened ; cotyledons slightly unequal, bilobed. — Sp. about 10; 5 in FL B. Ind. This is the section of Vatica called Eu-Vatica in Fl. B. Ind., but the fruiting cal. is quite unlike that of Vatica, and it cannot come under Linnaeus’ genus (see Trim, in Journ. Bot. x.xiii. 204). S. batttafnensis | genus = SUNAPTEA, epithet = batttafnensis, author = |
| Chrysops dispar (Fab) Wied., C. impar Rond. | I took the following note when I saw the type in Genoa, a single specimen: very like signifer Wk, only face altogether yellow; first abdominal segment yellow. May be only a paler variety” Chrysops dispar (Fab) Wied. A. Z. I, 196. I believe C. impar Rond. Ann. M, C. Gen. VII, 460, to be the same as dispar; I have seen the types. Tab anus. There are about a dozen species in the collection, most of which it would hopeless to recognize among the 120 described species of this genus from South-eastern Asia, as they show no striking distinctive characters. | genus = Chrysops, epithet = dispar, author = (Fab) Wied., genus = Chrysops, epithet = impar, author = Rond. |
Qualitative Evaluation
The formatted output demonstrates whether the model has located a term as genus, epithet, or author, and tends to have more expanded abbreviations (e.g. “C. impar” becomes “Chysops impar”). Many of the formatted examples only output a few names, whereas the unformatted output is more likely to list a longer set of names. However, the unformatted output is more likely to repeat the same scientific name multiple times, to attempt to mimic examples it received during training.
Quantitative Evaluation
I evaluated the degree of differences, information retained, and information added through a combination of string matching (with Levenshtein distance) and common classification measurements: precision, recall, and F1. If the document only includes a single scientific name, the model performs best with formatted output. If the document lists more than 2-3 names, the model retains the most information without additional formatting. Precision is consistently highest with formatted output, but information is often lost (harming recall) when outputting formatted text.
| Input Type | F1 | Precision | Recall |
| Single Names | |||
| Formatted | 0.845 | 0.84 | 0.84 |
| Unformatted | 0.838 | 0.834 | 0.833 |
| Multiple Names | |||
| Formatted | 0.60 | 0.69 | 0.617 |
| Unformatted | 0.692 | 0.689 | 0.679 |
Path Forward
While this performance is already relatively high, especially when a document has a single scientific name, there are steps toward improving its performance. Primarily, we could take a step back in the language-model training pipeline and continue pretraining (before fine-tuning) on biodiversity literature to create a “biological” language model–a model of how language operates in biodiversity documents. I prepared the groundwork for continued pretraining, as I collected a large dataset from the Biodiversity Heritage Library (BHL). The BHL’s data has a range of optical character recognition (OCR) quality, so I designed multiple tests for assessing the OCR quality of a given document. The resulting dataset includes 13 languages (Czech, English, French, German, Italian, Japanese, Latin, Norwegian, Polish, Portuguese, Russian, Spanish, and Swedish) and spans multiple centuries. This BHL dataset and OCR detection code will be released as an accompanying part of this project.
Impact
The fine-tuned language model can be incorporated into systems to aid with the identification and search indexing of archives about plants and animals. This project is an initial exploration into how advancements in text generation can enable biologists to study biodiversity, in context.
Citations
Little, D.P. 2020. Recognition of Latin scientific names using artificial neural networks. Applications in Plant Sciences 8(7): e11378.
